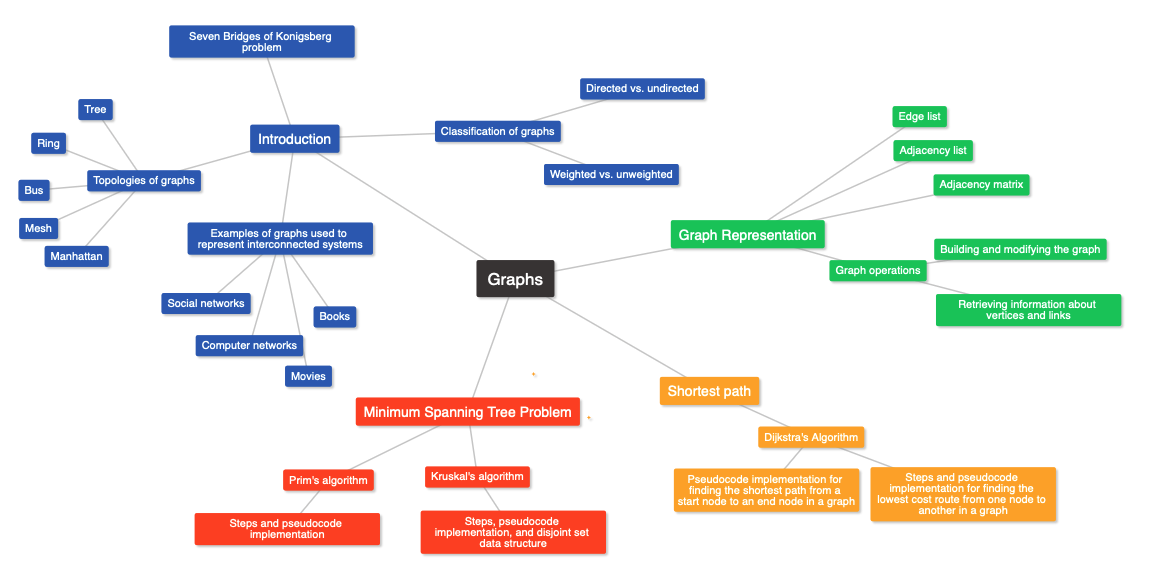
9 Graphs
Topic 10 is graphs, including their history, representation, topologies, and operations. The lectures discuss two algorithms, Prim’s algorithm and Kruskal’s algorithm, used to find the minimum spanning tree of a graph. Additionally, there are lectures explaining Dijkstra’s algorithm, used to find the lowest cost route from one node to another in a graph, and finding the shortest path from a start node to an end node. All discussed algorithms are presented with walk throughs and pseudocode.
9.1 Introduction to graphs
The lecture introduces the concept of graphs, a data structure used to represent interconnected systems. The history of the Seven Bridges of Konigsberg problem is presented as an example of how graphs were used to solve a mathematical problem. The transcript then presents various examples of graphs being used to represent different interconnected systems, including books, movies, computer networks, and social networks. The transcript also classifies graphs based on their directed or undirected nature and the weight associated with their links. Finally, the transcript mentions the different topologies of graphs, including the bus, ring, tree, Manhattan, and mesh topologies. The lecture concludes by highlighting that in the next lecture, graphs will be represented in a computer.
9.2 Graph representations
This lecture discusses the different ways of representing a graph data structure. Three representations are discussed: the edge list, adjacency matrix, and adjacency list. The edge list representation stores every link in the graph as a triplet; starting node, ending node, and the weight of the link. The adjacency matrix has the same number of rows and columns and contains numbers that represent the presence or absence of links and their weights. The adjacency list is an array of lists where each position represents a node, and the list contains information about outgoing edges. The lecture also covers the most common graph operations, including building and modifying the graph and retrieving information about vertices and links. The way graph operations are implemented depends on the selected graph representation. The lecture concludes by encouraging the audience to think about how to implement graph operations using the different representations.
9.3 Minimum spanning tree problem
The minimum spanning tree is a tree that includes all the nodes of a graph using the subset of edges with minimum total weight. This problem is useful in various scenarios, such as in the case of the men’s football World Cup where the minimum spanning tree is used to efficiently send data through the network of servers.
Prim’s algorithm starts by selecting any node in the graph to start building the tree and identifies all links that connect the nodes in the tree with the nodes not yet in the tree. The link with the minimum cost among them is selected, and the node connected to it is added to the minimum spanning tree. This process is repeated until all nodes are added to the tree.
Kruskal’s algorithm starts with V different trees, each made of one node. These trees start to merge until they form a single spanning tree. The merging of the trees is done one step at a time, and at each step, the minimum weight link connecting two different trees is chosen. This process is repeated until all trees are merged into one.
9.3.1 Prims algorithm
In this lecture, the pseudocode implementation of Prim’s algorithm for building the minimum spanning tree was discussed. Prim’s algorithm starts by initializing the tree with any vertex from the graph and then incrementally constructing the tree by finding the minimum weight link and adding it to the tree, as well as the node connected to that link. The pseudocode implementation includes initializing the minimum spanning tree, finding the set of links that connects nodes in the tree to nodes not yet in the tree, selecting the minimum cost link, and adding it along with the new node to the minimum spanning tree. The lecture also demonstrated the step-by-step execution of the pseudocode with a small graph. The pseudocode is kept general to apply to different representations of graphs. The lecture concludes by mentioning that the next lecture will review the pseudocode of Kruskal’s algorithm.
9.3.2 Kruskal’s algorithm
In this lecture, the pseudocode implementation of Kruskal’s algorithm for finding the minimum spanning tree of a graph was discussed. The three main steps of Kruskal’s algorithm were outlined, including the initialization of the tree with as many 1-node trees as there are nodes in the graph, sorting the edges of the graph in ascending order of weight, and selecting the next edge to add to the spanning tree by merging two trees with the lowest cost edge. The pseudocode implementation of Kruskal’s algorithm was presented, and the disjoint set data structure was briefly introduced. The steps were then demonstrated with a small graph, and the execution was simulated step-by-step.
9.4 Shortest path problem
9.4.1 Dijkstra’s algorithm
The lecture explains Dijkstra’s algorithm, a graph algorithm used to find the lowest cost route from one node to another in a graph. The algorithm involves initializing a table and set of unexplored nodes, and then updating the table by analyzing each node and checking if a route passing through that node is better than a previously recorded one. The algorithm continues until all nodes have been explored. The lecture provides an example to demonstrate the algorithm’s steps and shows how to read the routing table to obtain the shortest route from one node to another.
The lecture presents a pseudocode version of Dijkstra’s algorithm that finds the shortest path from a start node to an end node in a graph. The algorithm initializes a routing table and a set of unexplored nodes, selects the next unexplored node closest to the source node, calculates the distance from the source node to each of its neighbor nodes, updates distance and route information data if a shorter distance is found, and removes the explored node from the set of unexplored nodes. The input arguments for the pseudocode are the graph G, the start node, and the end node. The algorithm stops as soon as the route from start to end is found and pushes the sequence of previous nodes to a stack to return the route. A min-heap is used as the priority queue to select the next unexplored node with the shortest distance to the start node. The rest of the code processes the unexplored nodes, updates information, and returns the result.